موتور رلوکتانس با شبکه عصبي متلب
مشخصات موتور
موتور رلوکتانس متغیر (SRM)
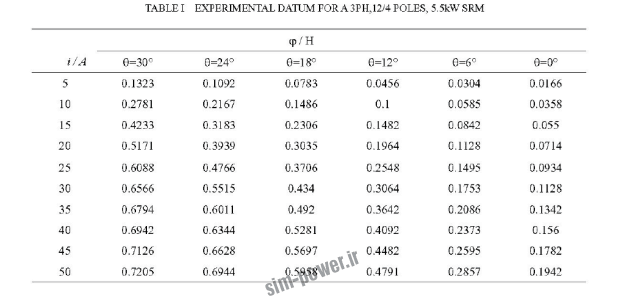
موتور از نوع سه فاز با قطبهای 4/12 و توان 5.5 کیلو وات
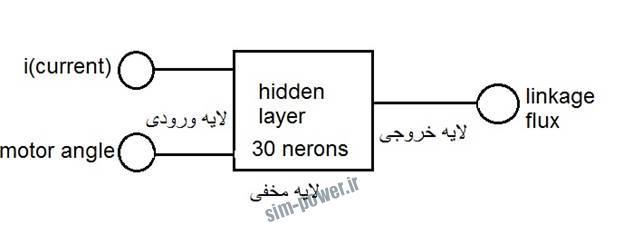
ورودی ها ی ما عبارت است از زاویه موتور بر حسب شش 6 درجه گردش موتور
جریان های متغیر
و خروجی ما میزان شار مغناطیسی اتصالی
تو شبکه عصبی به معادلات حاکم هیچ کاری نداریم. خود شبکه عصبی روابط رو با توجه به داده ها ی ورودی و نتایج حاصله از اون که همون خروجی های ماست (اینجا شار مغناطیسی) و بر اساس لایه پنهان و تعداد نرون ها باید بسازه. بعد از اون یک شبکه می سازه که با اون می تونیم هر چی داده داریم رو دوباره شبیه سازی کنیم.
مثلا می تونیم بهش زاویه موتور و جریان بدیم و نتیجه رو بهمون میده. در کل برای شبکه عصبی نیازی به دانستن روابط نیست. فقط باید داده تجربی داشته باشیم. داده ها توی مقاله اومده. توی فایل اکسل هم من دوباره نوشتم.
در ضمن مقاله از الگوریتم ژنتیک برای افزایش سرعت استفاده کرده که چون داده هامون کمه اصلا استفاده از الگوریتم ژنتبک منطقی نیست و باعث میشه شبکه به هم بریزه.
شبکه عصبی یک سری از داده ها رو به عنوان اموزش training و یک سری رو به عنوان اعتبار سنجی validation و یک سری رو هم به عنوان ازمون test در نظر می گیره. اینکه چه میزان داده رو برای هر بخش انتخاب کنه رو می شه تغییر داد که تو این پروژه 70، 15 و 15 درصد به ترتیب برای امورشريال اعتبار سنجی و ازمون در نظر گرفتم. از بین داده ها به طور تصادفی موارد رو انتخاب می کنه و شبکه رو می سازه. برای ساخت شبکه چند مورد مهم یکی تابع اموزش، نوع تعیین ضرایب برای داده های لایه پنهان و لایه خروجی که برای هر کدوم تابع های مختلفی داره. و اما بین ورودی ها و خروجی ها یک سری لایه های پنهان شبکه عصبی درست می کنه که تعدادی نروند اره که این نرون ها بین ضرایب داده های ورودی و لایه خروجی با توجه به داده ها یک سری اتصالات بر قرار می کنه. نهایتا با اموزش، اعتبار سنجی و ازمون شبکه رو مشخص می کنه.
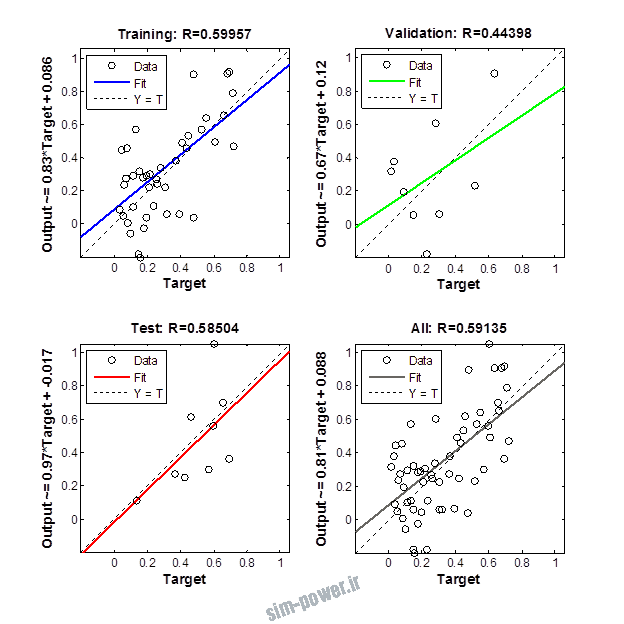
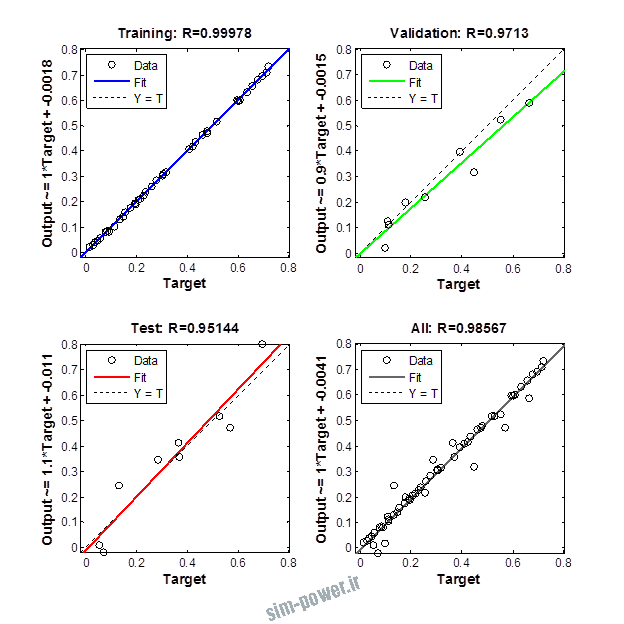
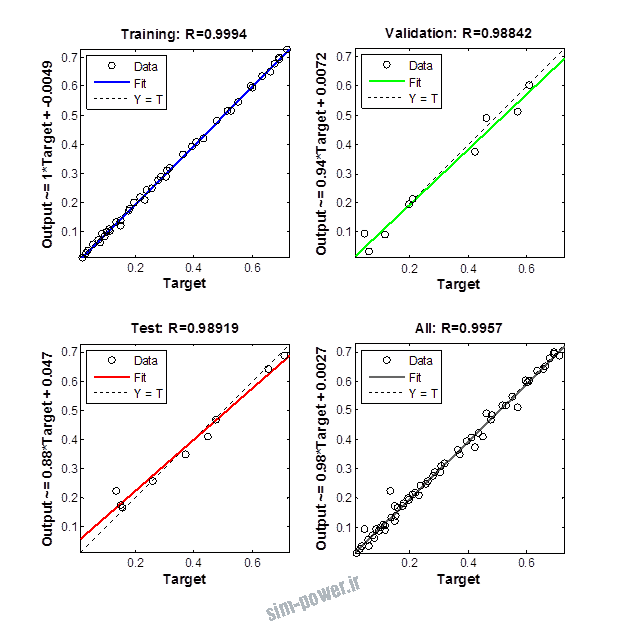
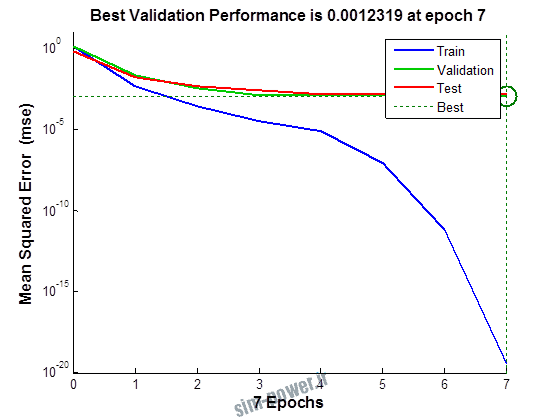
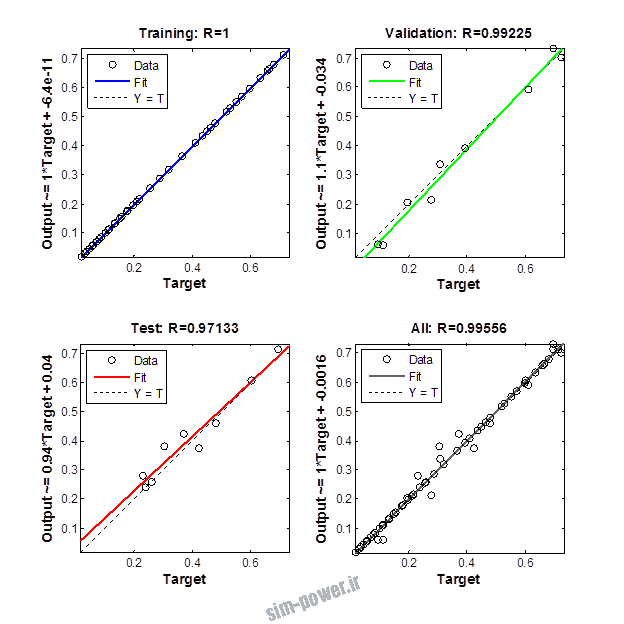
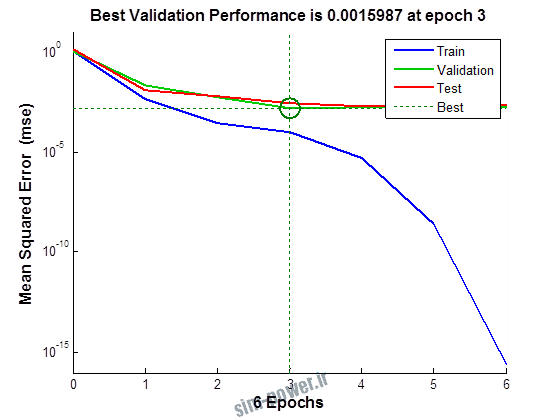
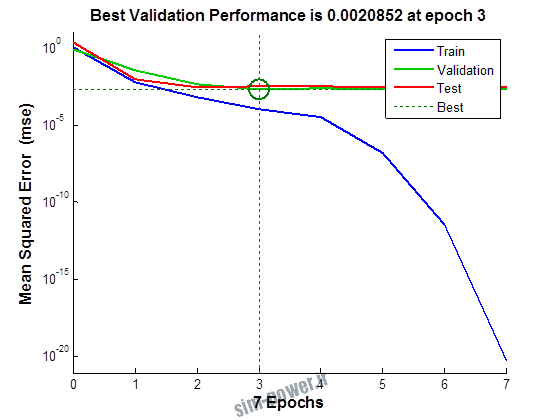
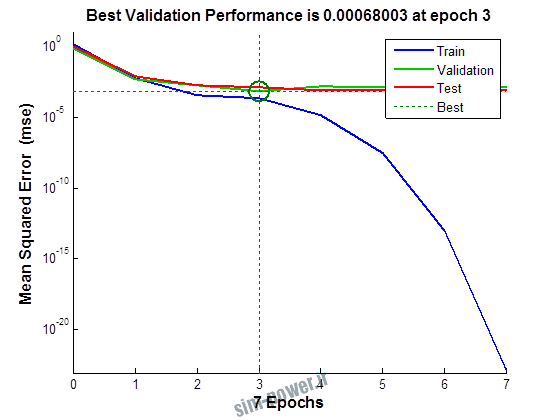
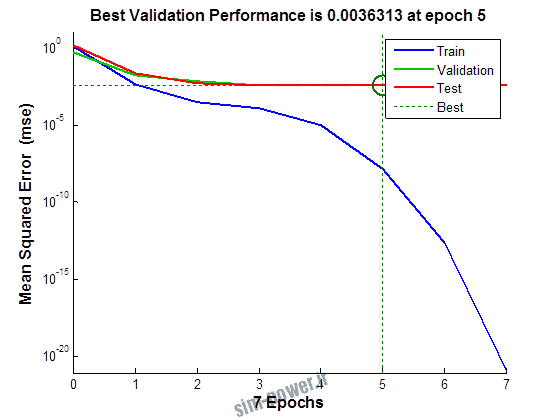
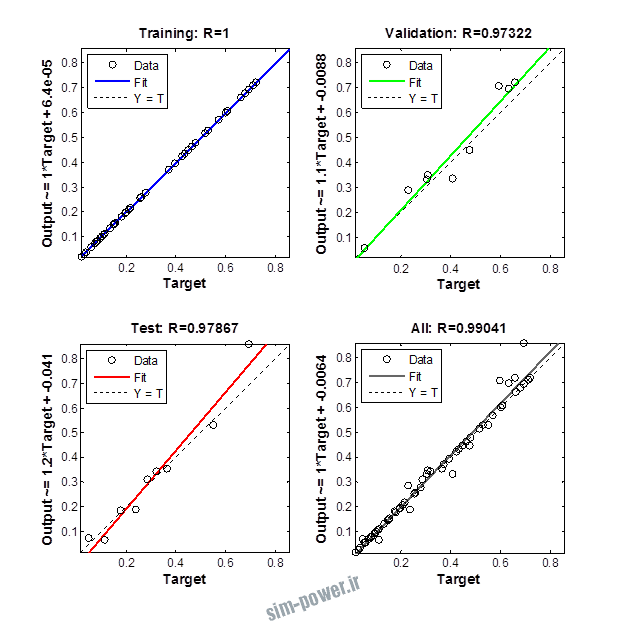
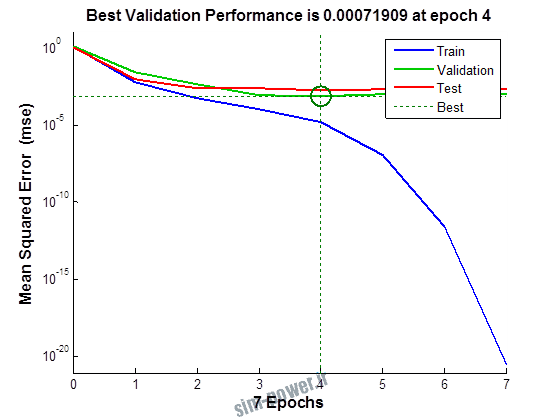
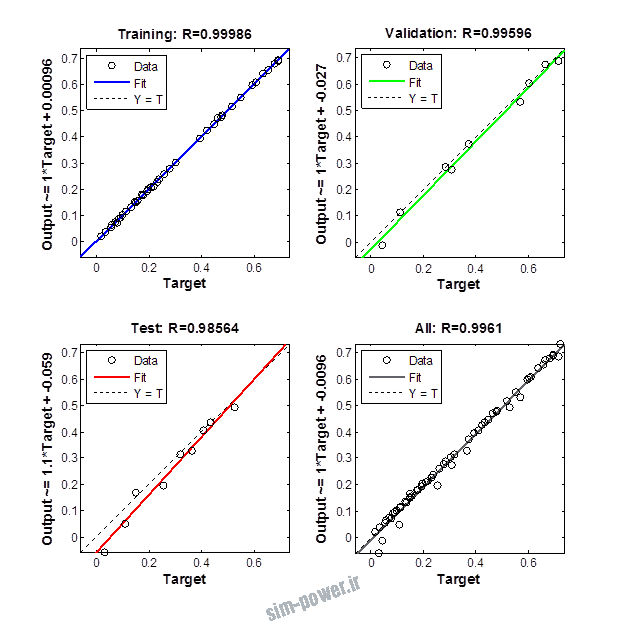
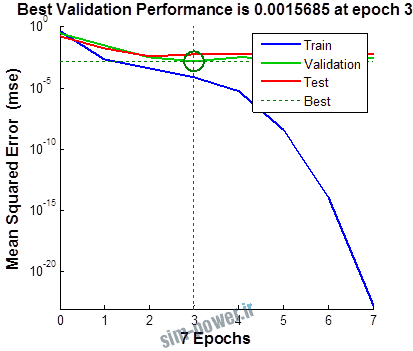
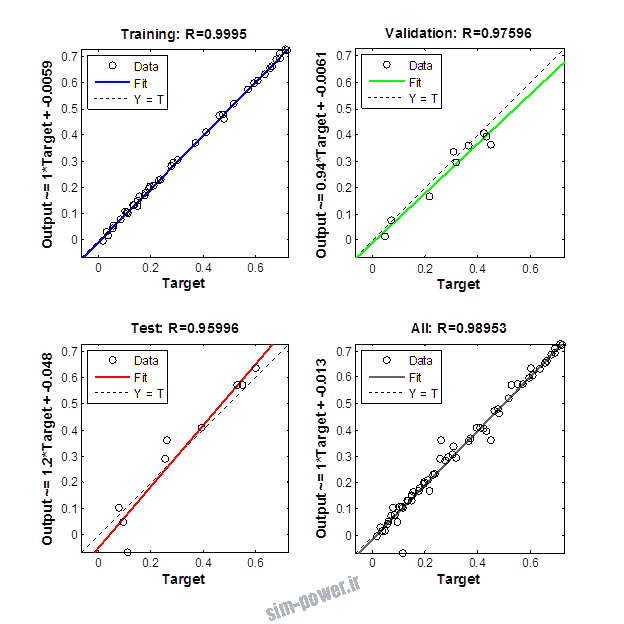
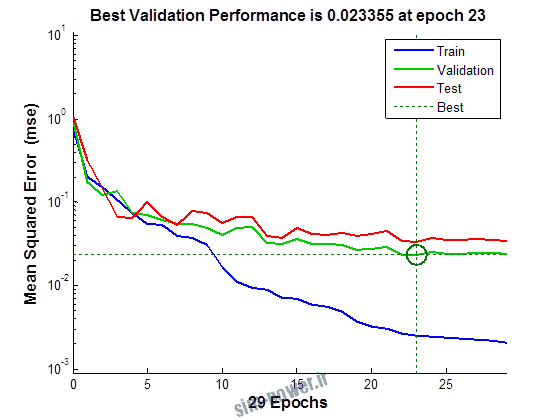
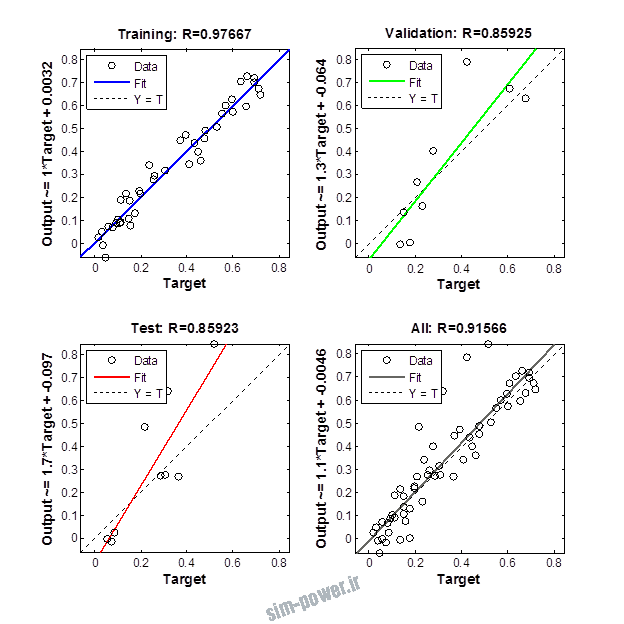
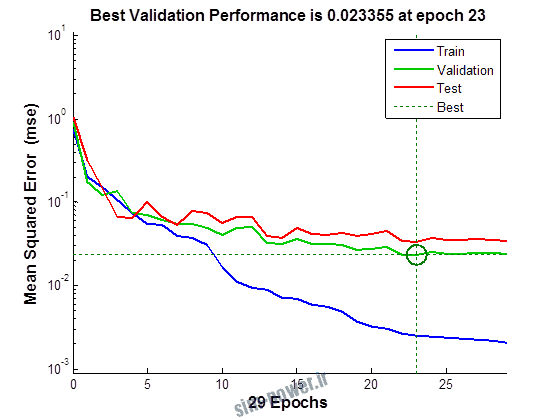
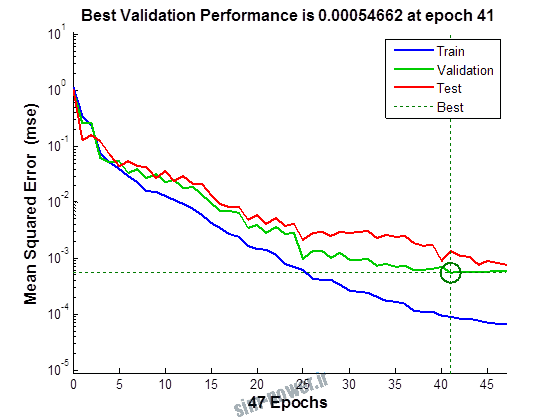
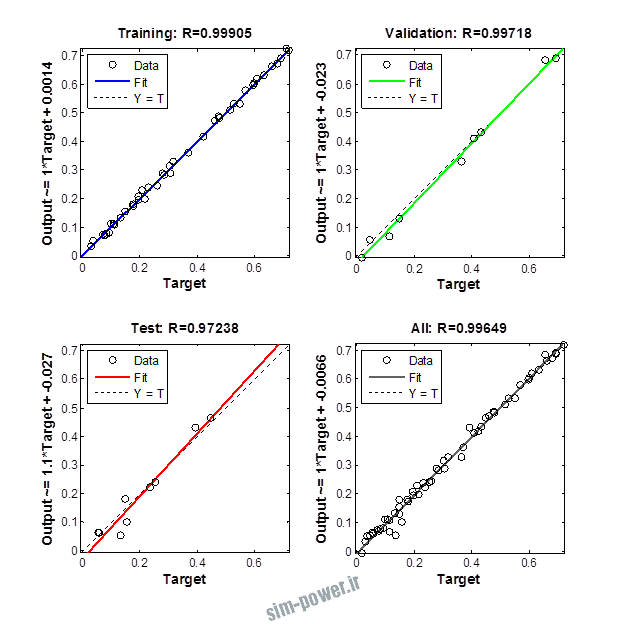
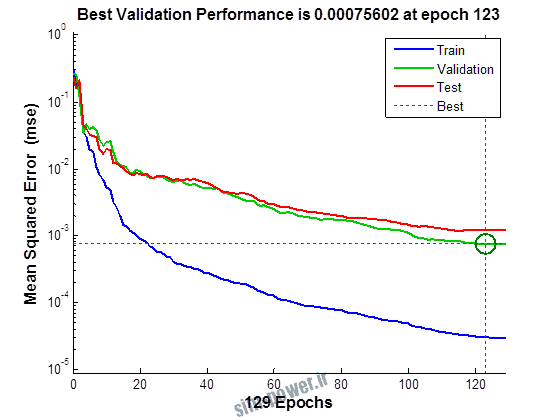
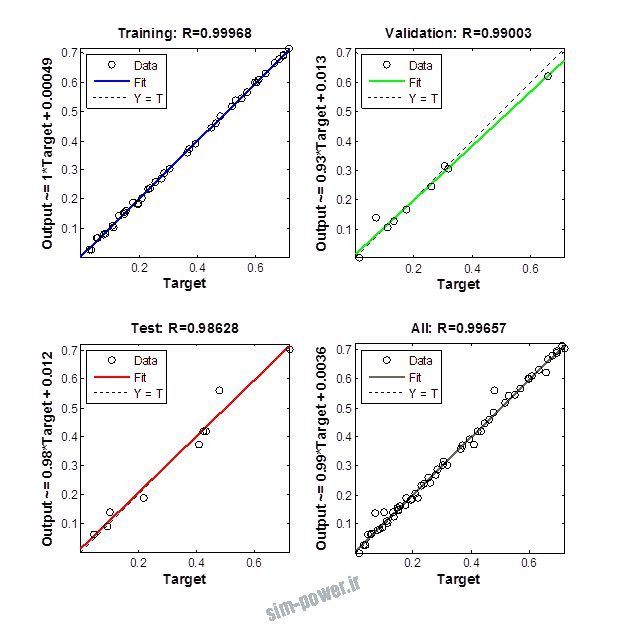
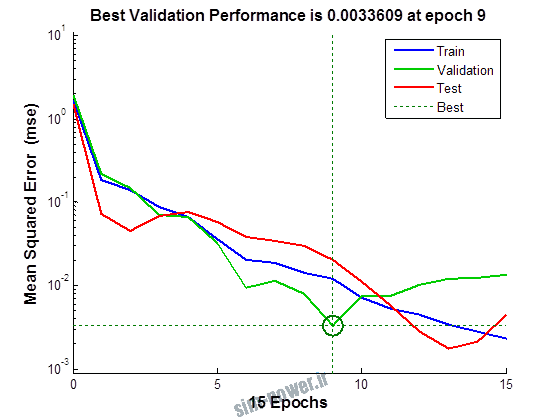
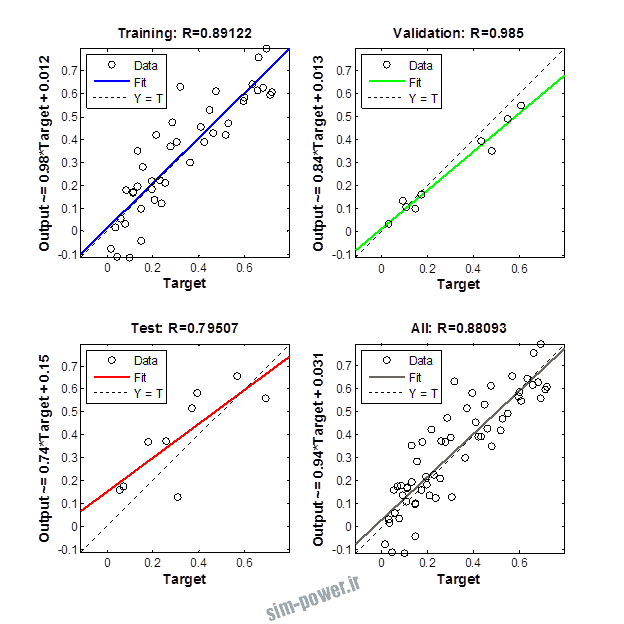
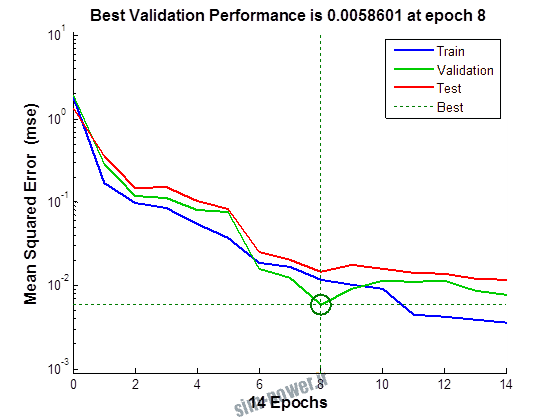
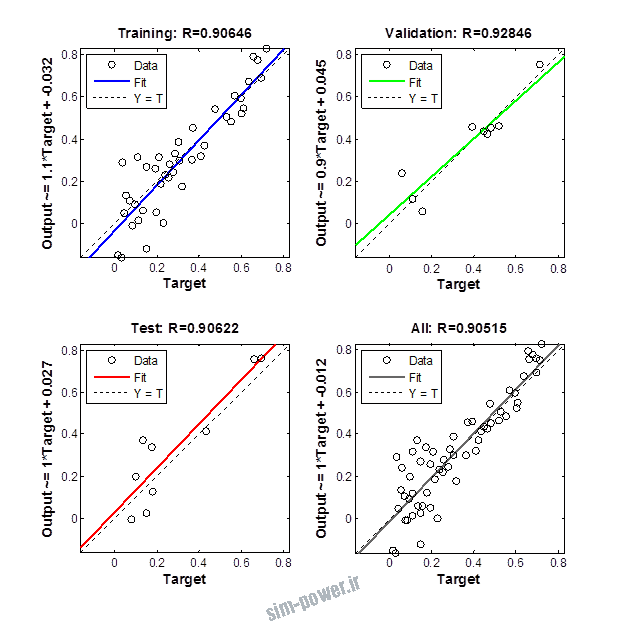
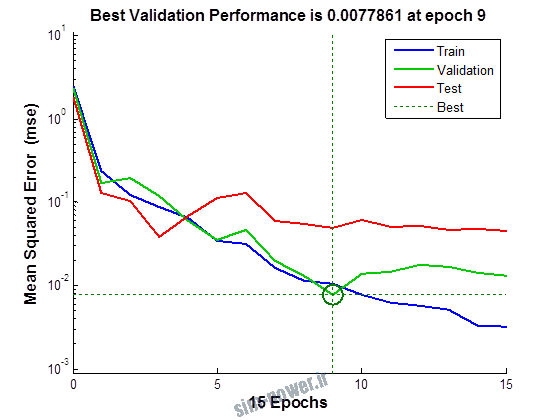
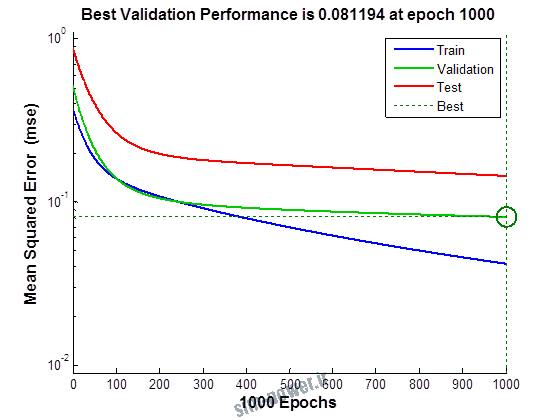
راجع به شبکه عصبی باید دو چیز رو در نظر داشت. یکی R ضریب رگرسیون هست و اون یکی MSE متوسط خطای مربعات.
هرچه R به یک نزدیک تر باشه و MSE به صفر نزدیک تر باشه نشان دهنده اینه که شبیه سازی انجام شده و در حقیقت اموزش شبکه عصبی بهتر بوده.
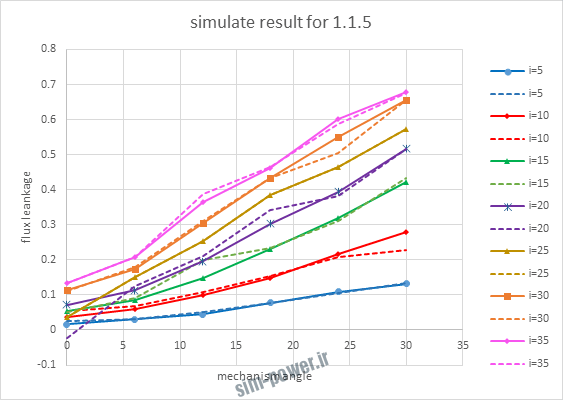
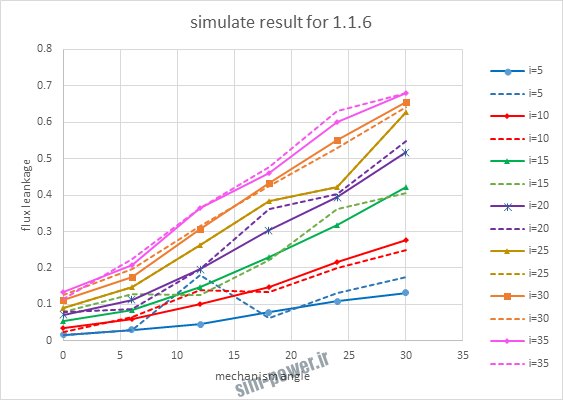
حالا تو این پروژه من برای شبکه های مختلف میزان این دو متغیر رو بررسی کردم و از بین نمونه های مشخص شده اون هایی که R نزدیک به 1 (0.994-0.996) داشت و SME نزدیک به صفر (10-3) رو مشخص کردم. بعد با توجه به شبکه ساخته شده داده ها رو شبیه سازی کردم و بین داده های اولیه (شار مغناطیسی) و داده های به دست اومده از شبکه عصبی مقایسه کردم که توی نمودار ها نتایجش هست.

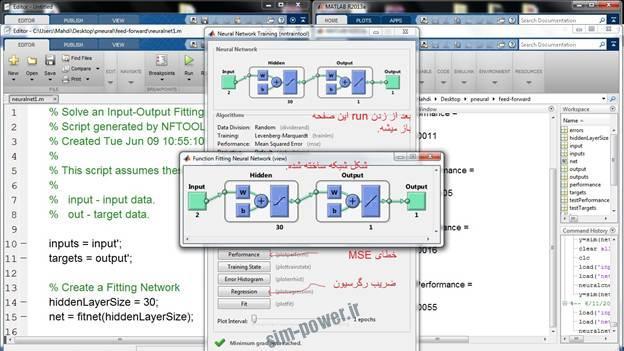
برای اجرا دو تا فولدر هست که توش یک سری ام فایل و دو تا فایل .mat هست. ام فایل ها رو توی محیط ادیتور )editor ctrl+N) و توی workspace باز کنید. بعد هم دکمه run رو بزنید. یک صفحه باز می شه.
توی صفحه روی گزینه هایی که توی شکل مشخص شده کلیک کنید. تا mse و R برای قسمت های مختلف نشون داده بشه.
Nonlinear Modeling of Switched Reluctance Motor Based on Neural Network
در این پروژه موتور القایی متغیر توسط شبکه عصبی متلب مدل شده است. داده ها از مرجع 1 گرفته شده است. داده های ورودی شامل زاویه موقعیت موتور و جریان فاز بوده و خروجی اتصال مغناطیسی می باشد.
برای شبیه سازی از شبکه های مختلف با تعداد لایه ها و نرون های مختلف استفاده شده است. میزان دقت در پاسخگویی به متغیر R مقدار رگرسیون بستگی دارد که هر چه به یک نزدیک تر باشد نشان دهنده دقت بیشتر در ارتباط بین خروجی و هدف است. مقدار 1 ارتباط کامل و 0 عدم ارتباط بین خروجی ها و هدف را نشان می دهد. برای اموزش شبکه عصبی به طور تصادفی از 70 درصد داده ها استفاده شده است و 15 درصد برای اعتبار سنجی و 15 درصد برای ازمون شبکه استفاده شده است.
برای لایه پنهان 30 نرون در نظر گرفته شده است که مطابق با میزان نرون های در نظر گرفته شده در مرجع 1 می باشد.
نتایج حاصله برای شبکه های مختلف ایجاد شده در زیر امده است.
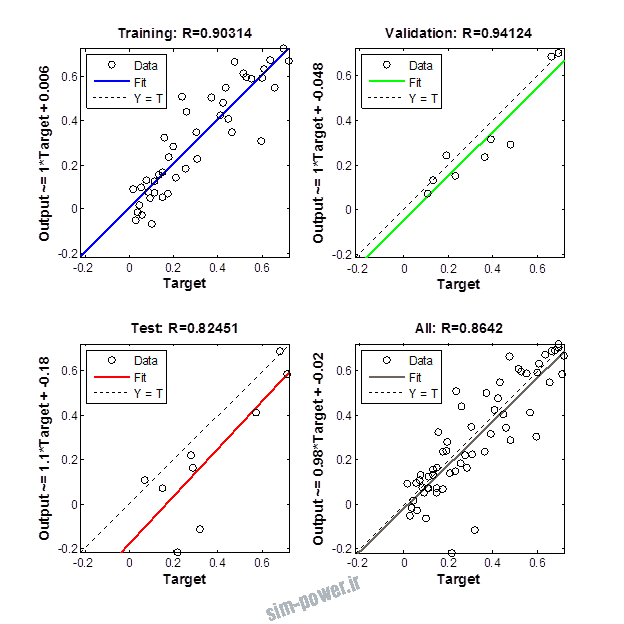
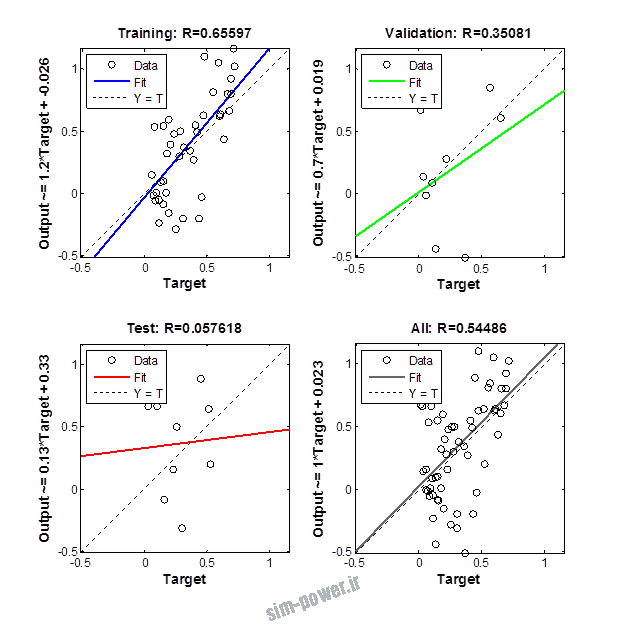
نمودار های به دست امده عبارت است از نمودار عملکرد و نمودار رگرسیون که هرچه میزان ضریب رگرسیون R به یک نزدیک تر باشد میزان دقت شبکه بیشتر است.
- شبکه BP Backpropagation Training algorithms
شبکه از نوع BP با توابع مختلف برای لایه مخفی و خروجی مورد بررسی قرار گرفته است که نتایج در ادامه امده است.
برای توابع لایه مخفی و خروجی سه نوع تابع وجود دارد که عبارت اند از تابع تانژانت سیگموئید، تابع خطی و تابع لگاریتم سیگموئید، و در این پژوهش توابع مختلف برای لایه مخفی و خروجی مورد بررسی قرار گرفته اند.
به علاوه برای اموزش از توابع مختلف می توان استفاده کرد که هر یک بر روی عملکرد شبکه تاثیر به سزایی دارد. 13 تابع اموزش وجود دارد که برای انتخاب بهترین گزینه توابع مختلف نیز بررسی شده است. تابع عملکرد MSE در نظر گرفته شده و نتایج در ادامه اورده شده است.
1.1 شبکه از نوع Feed-Forward و تابع لایه مخفی tansig و لایه خروجی purelin
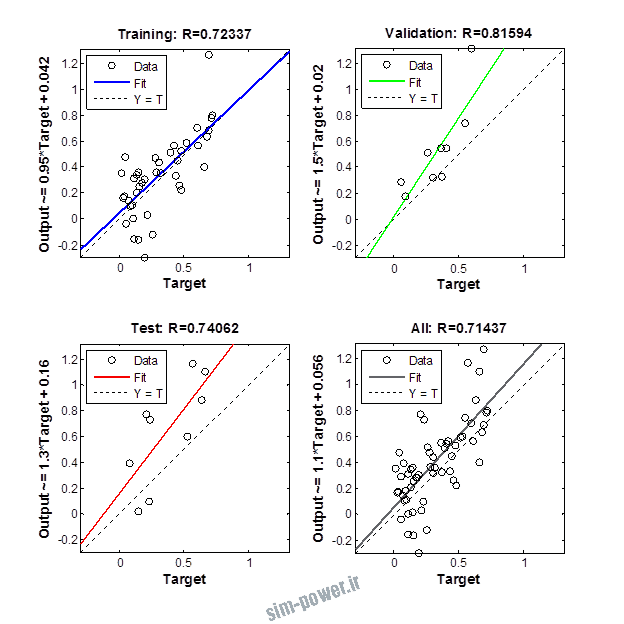
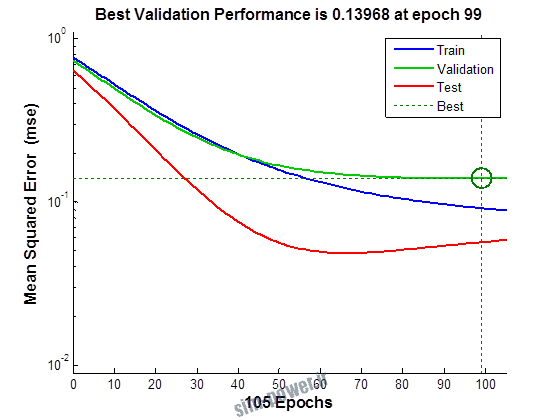










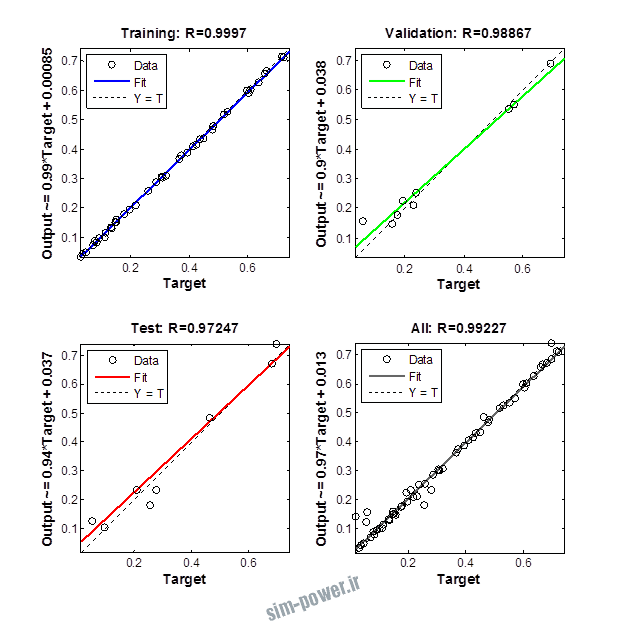
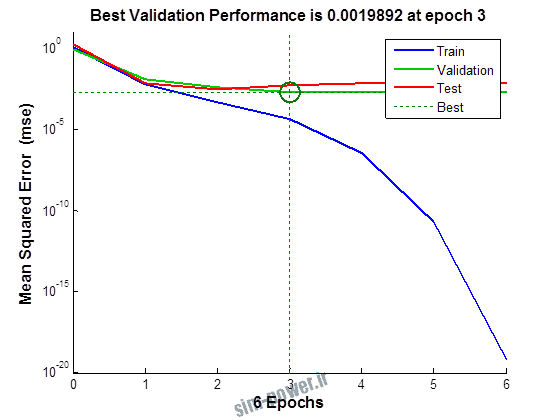
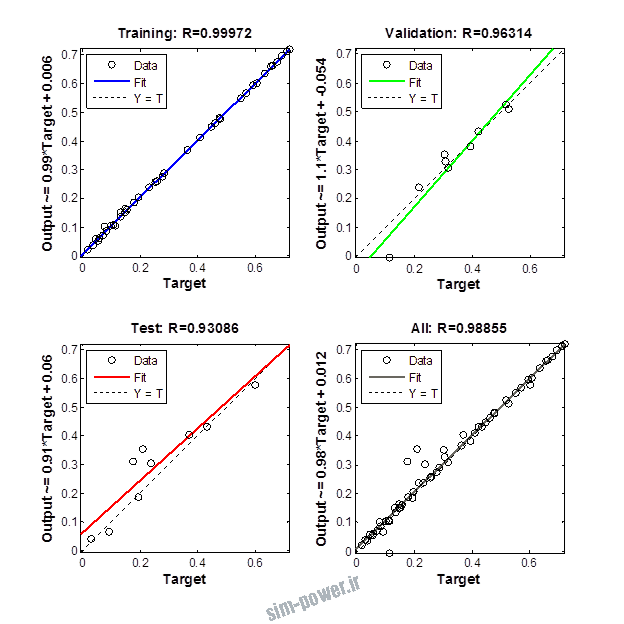

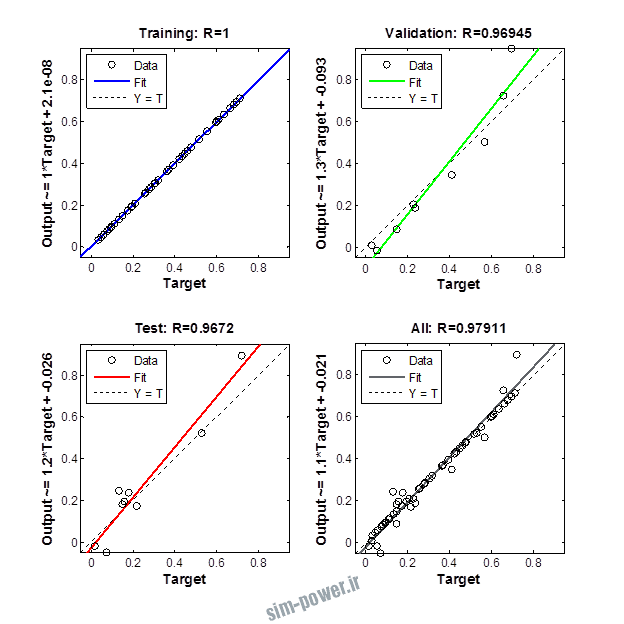
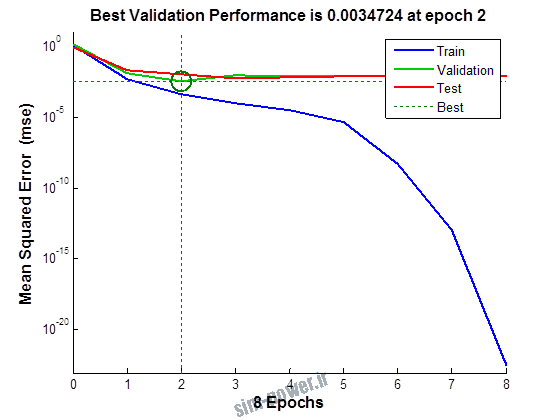
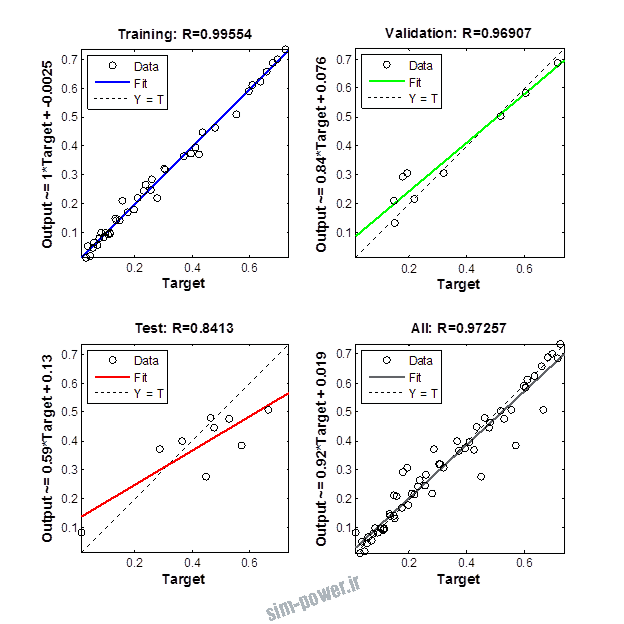
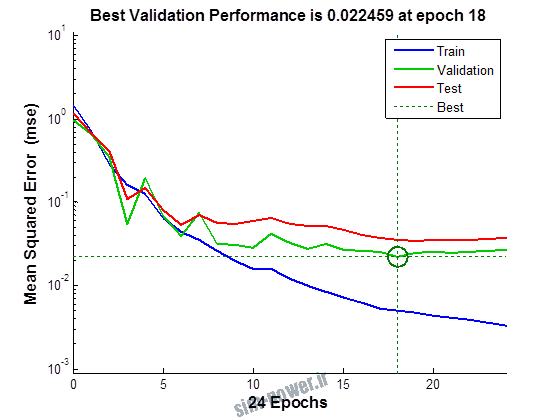
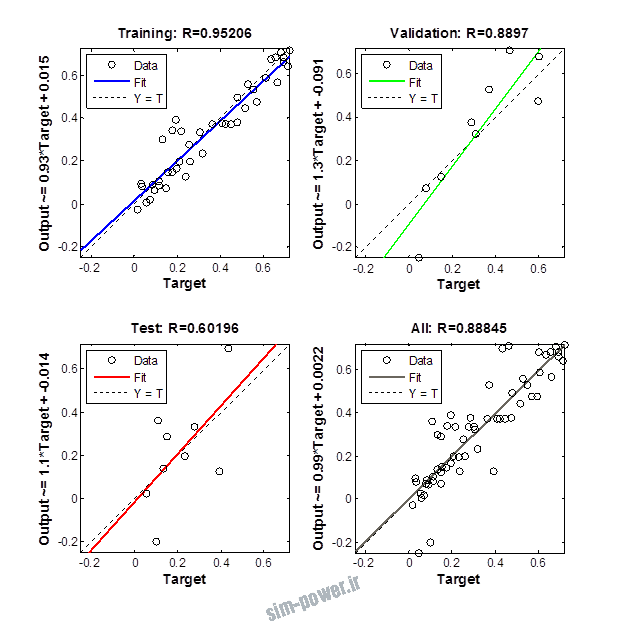

1.2. شبکه از نوع Cascade-Forward BP و لایه مخفی از نوع tansig و لایه خروجی purelin
1.2.1
از بین موارد به دست امده مشاهده می شود که موارد زیر خطای MSE کمتری دارند و میزان R انها به یک نزدیک تر است.
| مورد | MSE | R |
| 1.1.5 | 4*10-3 | 0.9964 |
| 1.1.6 | 3*10-3 | 0.9965 |
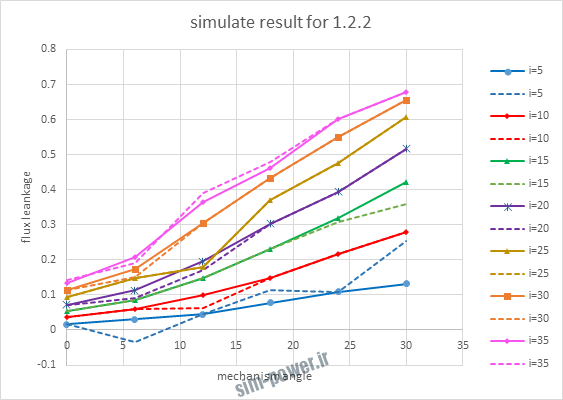
| 1.2.2 | 10-3 | 0.995 |
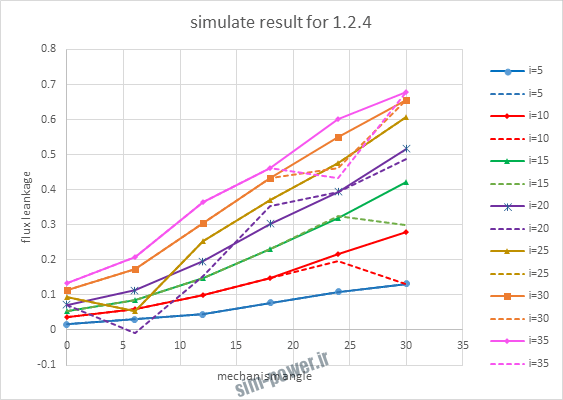
| 1.2.4 | 10-3 | 0.995 |
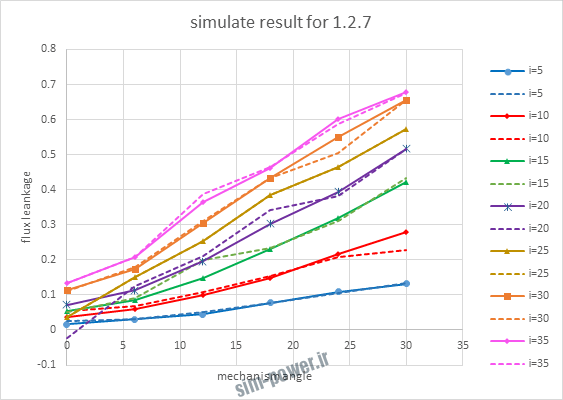
| 1.2.7 | 10-3 | 0.994 |
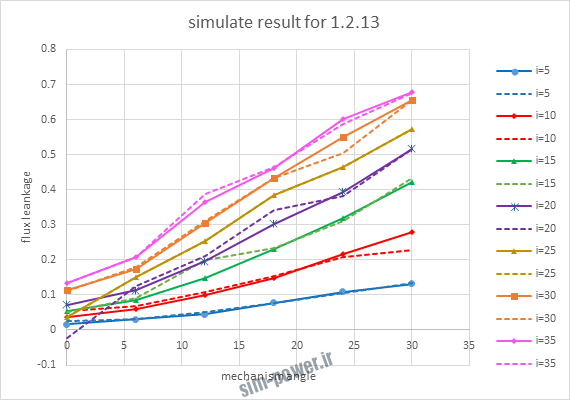
| 1.2.13 | 10-3 | 0.996 |
نتایج حاصل از شبیه سازی شبکه در زیر امده است.
با توجه به نمودار ها مشخص می شود که میزان شبیه سازی برای موارد 1.1.5 و 1.2.2 و 1.2.13 بهتر از بقیه موارد است.







سلام خسته نباشید
آیا شما می تونید شبکه عصبی را به همین شیوه برای تخمین موقعیت موتور سوئیچ رلوکتانسی طراحی کنید؟ ورودی شبکه جریان و شار و خروجی موقعیت تخمینی میشه. موتور چهار فازه و در سرعت نامی کار می کنه.