
“خوشهبندی هوشمند دادهها با الگوریتم Mean Shift: راهکاری بدون نیاز به تعیین تعداد خوشهها!”
﷼1.950.000
توضیحات
خوشهبندی دادهها با استفاده از الگوریتم Mean Shift
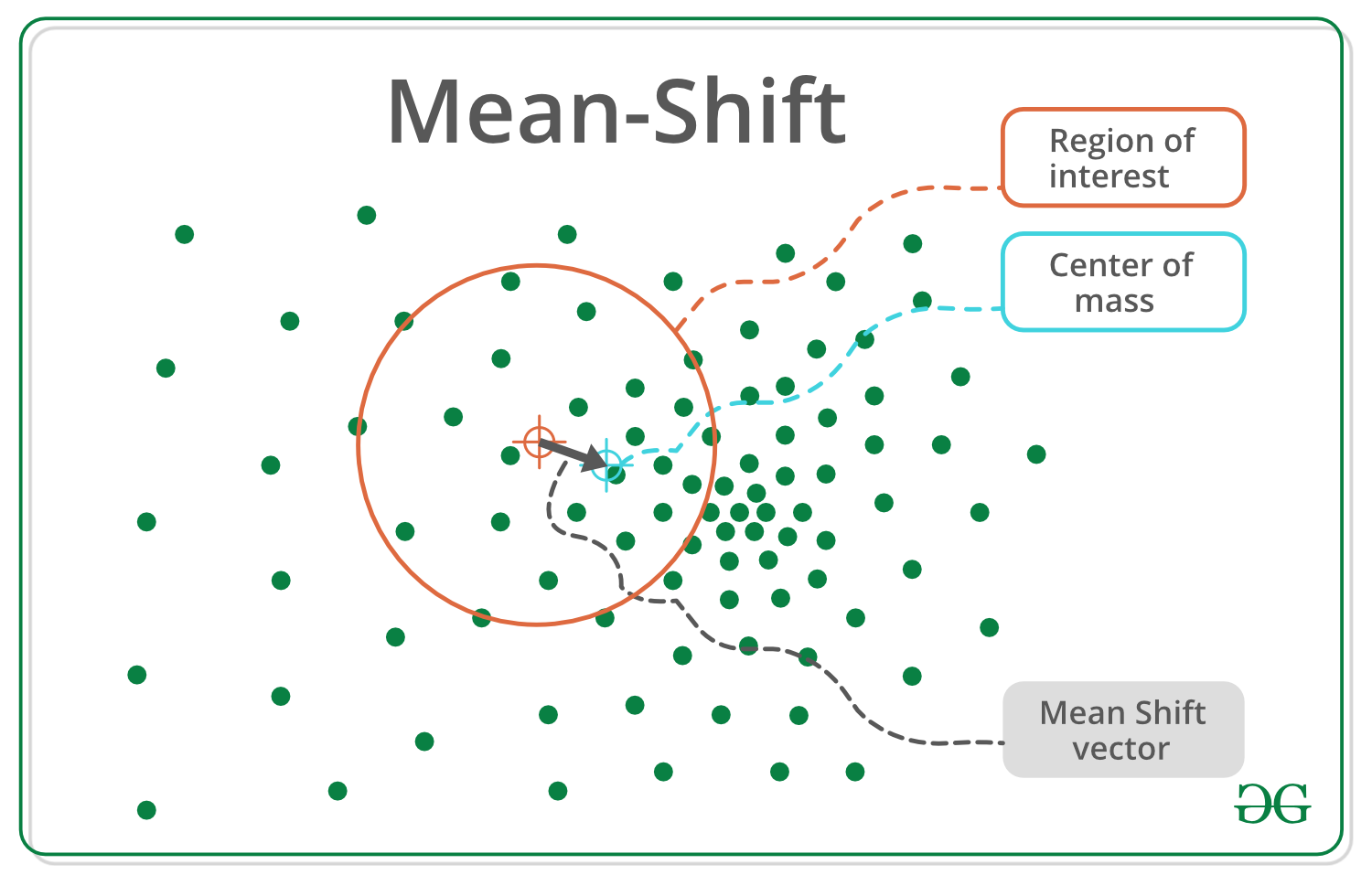
الگوریتم Mean Shift یکی از روشهای قدرتمند و غیرپارامتری در یادگیری ماشین است که برای خوشهبندی دادهها استفاده میشود. این الگوریتم بدون نیاز به مشخص کردن تعداد خوشهها از پیش، دادهها را بر اساس چگالی نقاط در فضای ویژگی گروهبندی میکند.
نحوه عملکرد الگوریتم Mean Shift
الگوریتم Mean Shift بر اساس حرکت نقاط داده به سمت مراکز چگالی بالا کار میکند. به این صورت که در هر تکرار، یک نقطه انتخاب میشود و مقدار میانگین نقاط همسایهی آن در یک شعاع خاص (bandwidth) محاسبه شده و نقطه مورد نظر به این مقدار میانگین منتقل میشود. این فرآیند تا زمانی ادامه مییابد که نقطه به یک مقدار پایدار همگرا شود و دیگر تغییر نکند. در نهایت، نقاطی که به مکانهای مشابه همگرا شدهاند، در یک خوشه قرار میگیرند.
جزئیات کد و ورودیهای تابع
تابع meanShiftClustering که در کد پیادهسازی شده است، دادهها را دریافت کرده و خوشهبندی را انجام میدهد. این تابع ورودیهای زیر را دارد:
data: این متغیر ماتریسی با ابعاد (n×d) است که شامل نقاط دادهای است که باید خوشهبندی شوند.nتعداد نمونههای داده وdتعداد ویژگیهای هر داده است.bandwidth: این مقدار تعیین میکند که چه محدودهای از دادهها به عنوان همسایه برای محاسبه میانگین در نظر گرفته شوند. این پارامتر تأثیر زیادی بر عملکرد و دقت خوشهبندی دارد.plotFlag: اگر مقدار این متغیرtrueباشد، روند همگرایی نقاط و خوشهبندی نهایی به صورت تصویری نمایش داده میشود (این قابلیت فقط برای دادههای دو بعدی قابل مشاهده است).
مراحل اجرای کد
- مقداردهی اولیه و تعیین حداکثر تعداد تکرار (
maxIter) و آستانه همگرایی (tol). - انتخاب یک نقطه از مجموعه دادهها و محاسبه فاصلهی آن با سایر نقاط.
- تعیین مجموعهای از نقاط که در فاصلهای کمتر از
bandwidthقرار دارند. - محاسبه میانگین این نقاط و حرکت نقطهی مورد نظر به سمت این مقدار میانگین.
- تکرار این فرآیند تا زمانی که تغییرات کوچکتر از مقدار آستانهی
tolباشد. - اختصاص دادن نقاط به خوشههای نهایی و در صورت فعال بودن
plotFlag، نمایش خروجی.
توابع کمکی در کد
findOrCreateCluster: این تابع بررسی میکند که آیا نقطهی همگرا شده به یک خوشهی موجود تعلق دارد یا باید یک خوشهی جدید برای آن ایجاد شود.visualizeClustering: این تابع خوشههای ایجاد شده را به صورت یک نمودار رنگی نمایش میدهد که هر خوشه دارای رنگ متفاوتی است.
مزایا و معایب الگوریتم Mean Shift
✅ مزایا:
- نیازی به تعیین تعداد خوشهها از قبل ندارد.
- میتواند خوشههایی با شکلهای غیرکروی را شناسایی کند.
- نسبت به مقداردهی اولیه حساسیت کمتری دارد.
❌ معایب:
- محاسبات آن مخصوصاً برای دادههای ابعاد بالا سنگین است.
- انتخاب مقدار مناسب
bandwidthتأثیر زیادی بر نتیجهی نهایی دارد و یافتن مقدار بهینه دشوار است.
جمعبندی
الگوریتم Mean Shift یکی از روشهای مناسب برای خوشهبندی دادهها است که به صورت غیرپارامتری و بدون نیاز به مشخص کردن تعداد خوشهها عمل میکند. این الگوریتم با محاسبه چگالی دادهها و حرکت نقاط به سمت بیشترین تراکم، خوشههای طبیعی داده را استخراج میکند. در صورتی که دادههای شما دارای چگالی مشخصی باشند، این روش میتواند عملکرد خوبی داشته باشد.


نقد و بررسیها
هنوز بررسیای ثبت نشده است.