ابتدا میتوانید یک ویدیو درباره این مطلب ببینید
این برنامهای است که برای شما آماده کردهایم. همانطور که در قسمت Current Folder میبینید، برنامه از چند قسمت تشکیل میشود:
از یک اکسل تشکیل شده است:
که اطلاعات تعداد 69 باس را در این قسمت جمعآوری کردهایم. اطلاعاتی که جمعآوری شده است مربوط به اطلاعات استاندارد 69 باسهی ieee است:
همانطور که میبینید در سطر اول از باس 0 تا 1 میزان R و X را داریم و برای هر کدام از این باسها خطوطی که آنها را به یکدیگر مرتبط میکنند را در این سیستم دیدهایم. میزان 69 باس را به این جهت انتخاب کردهایم که نشان بدهیم به هر تعداد این سیستم ما قابل تعمیم است و همانطور که میبینید از تعداد 33 باس هم بیشتر است و میبینید (شکل زیر) مثلاً بین باس 68 و باس 69 یک خط هست که میزان اهم آن برابر 0.0047 و میزان X آن هم برابر 0.0016 است که بر حسب اهم دارید میبینید:
در ابتدا لازم بود که اینها را توضیح بدهم.
یک ماتریس دیگری هم اینجا داریم:
ماتریسی است که توانهای P و Q را برای ما در 69 باسه اندازهگیری میکند که اندازهی P و Q هر کدام از آنها مشخص شده است:
مثلاً در باس 6، ۲ کیلووات P و 2.2 کیلووار هم Q داریم و همهی باسها مشخص شدهاند که میزان توانی که جذب میکنند به چه نحوی است. اعدادِ اینها برگرفته از استاندارد 69 باسه ieee است.
و یک ماتریس هم data داریم که سایر دیتاها را میگیریم:
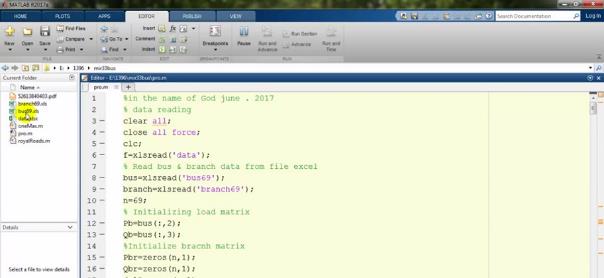
clear all و close all force برای این است که تمام پنجرههای قبلی بسته شوند و متغیرهای قبلی پاک بشوند. clc هم برای پاک شدن command window است که قطعاً با آن آشنایی دارید:
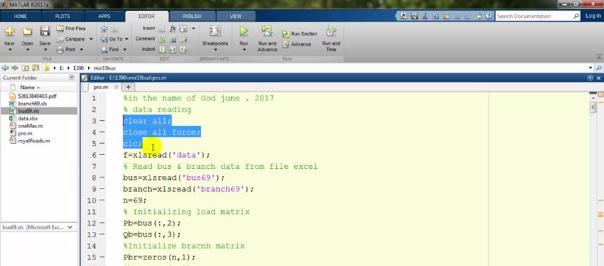
با سه دستور xlsread سه تا فایل اکسلمان را در متلب فراخوانی میکنیم. f را برای data، bus را برای باسهای 69 باسهمان و branch را برای شاخهها در نظر گرفتهایم. n هم تعداد باسهاست که اینجا برابر 69 قرار دادهایم.:
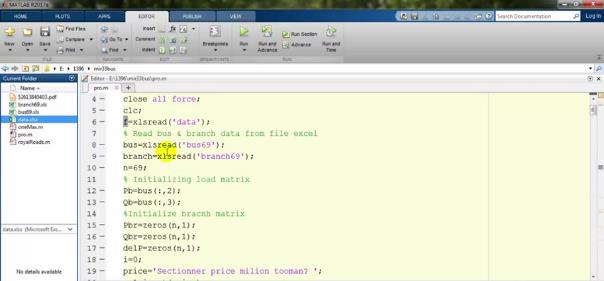
یک load matrix نیاز هست که استخراج کنیم که میزان P و Q را از داخل bus که از روی سه تا اکسل خواندیم، استخراج میکنیم. میگوییم که متغیر bus ستون دومش را برابر P قرار بدهد:
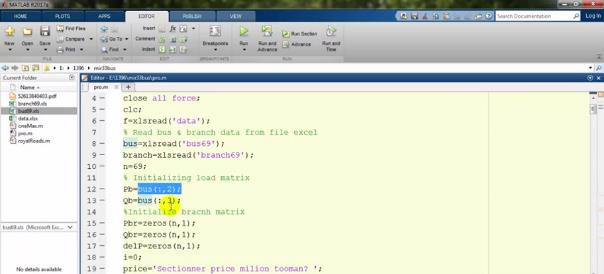
همانطور که در اینجا دیدیم:
ستون دومش برابر P است و ستون سومش برابر Q است که آن دو دستور به این معنا هستند. Pbr و Qbr را فعلا برابر صفر قرار دادهایم که بعداً از آن استفاده کنیم:
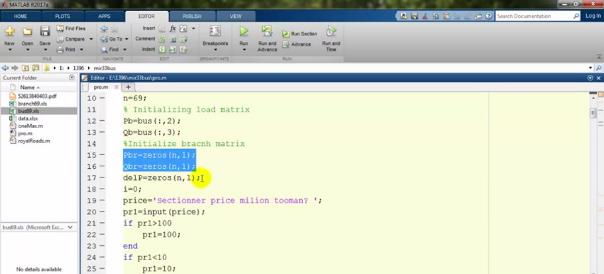
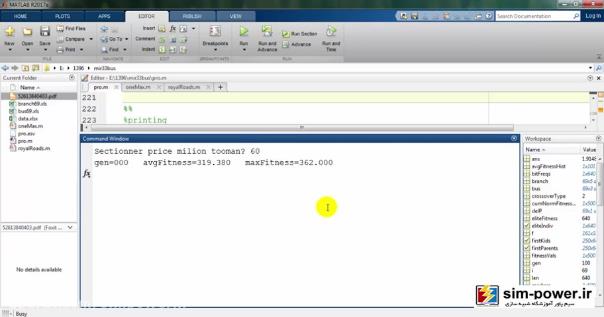
متغیر delp را هم تعریف کردهایم. i را هم اینجا برابر صفر میگیرم. یک متغیر price هست که هزینه sectioner است که شما خیلی روی آن تأکید داشتید، ما آمدیم و این را به صورت variable گرفتیم؛ یعنی اینکه میتوانید آن را به هر اندازهای که میخواهید تغییر دهید. میانگین ارزش sectionerهایتان را بر حسب price آن در نظر گرفتهایم که عددی بین ده تا صدمیلیون است که هزینهی معمول sectionerهاست:
اگر بالاتر از صدمیلیون باشد آن را برابر صدمیلیون درنظر میگیرم:
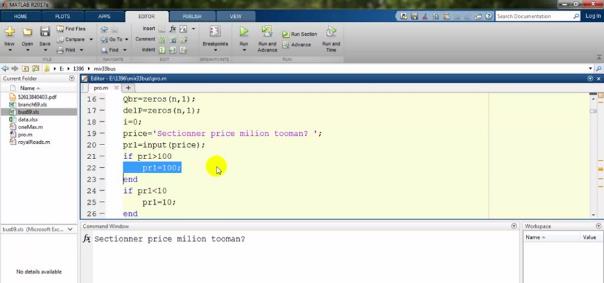
و اگر فرد به اشتباه زیر ده میلیون وارد کند حداقل برابر ده قرار میگیرد:
همانطور که اینجا میبینید اگر 10 را پایینترین عدد در نظر بگیریم، برنامه شروع میکند به run کردن و بعد از مدتی یک سری نتایجی را به ما میدهد:
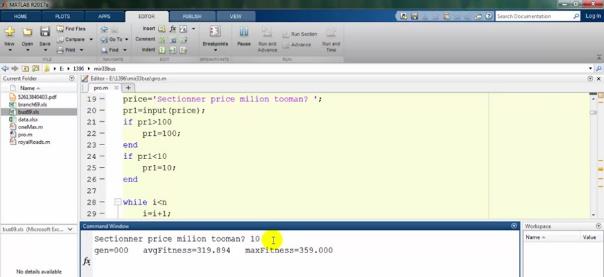
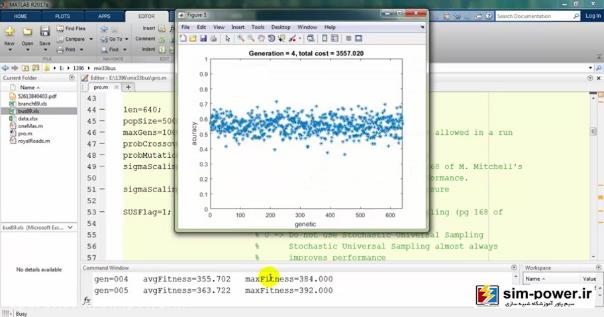
حالا چون run کردیم، اجازه دهید که نتایج را هم ببینیم. میبینید که با استفاده از ژنتیک میآید و با یک accuracy صد درصد fit میکند:
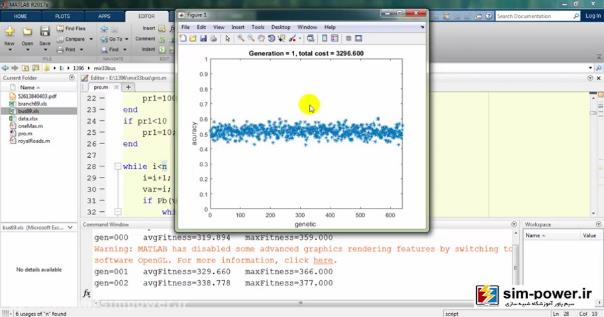
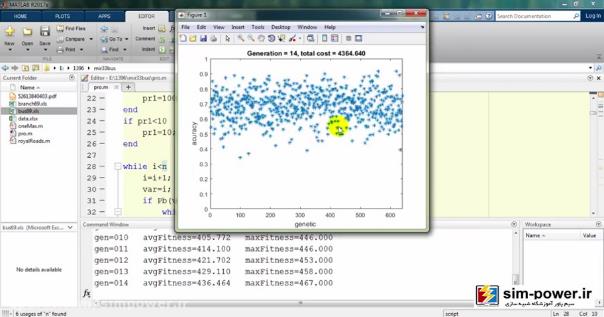
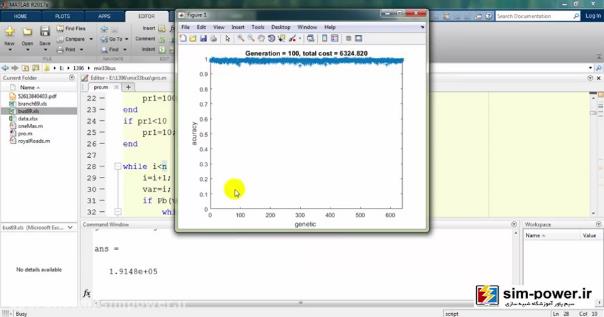
و برایمان یک سری گرافهایی را رسم میکند:
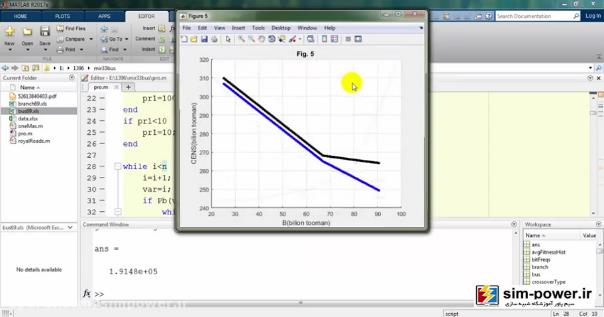
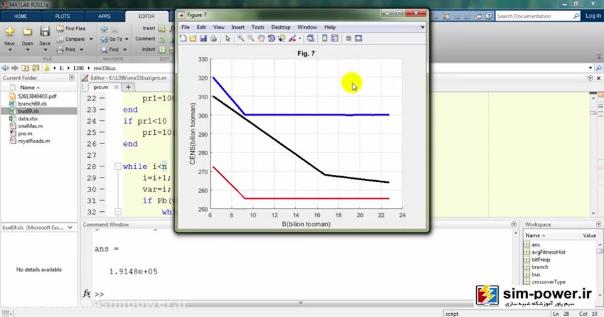
که در ادامه دربارهی آن توضیح خواهیم داد.
خب در اینجا میگوییم تا زمانی که i از تعداد باسها زیادتر بود و چنانچه P و Q مخالف صفر بود Pbr را با Pb(i) جمع کن؛ میخواهیم مجموعهی بارهایی که بر یک باس سوار هستند را در اینجا حساب کنیم:

یک دلتا هست که این دلتا را بر اساس فرمولهایی که در درسهای بررسی دوم خواندهاید محاسبه میکنیم:
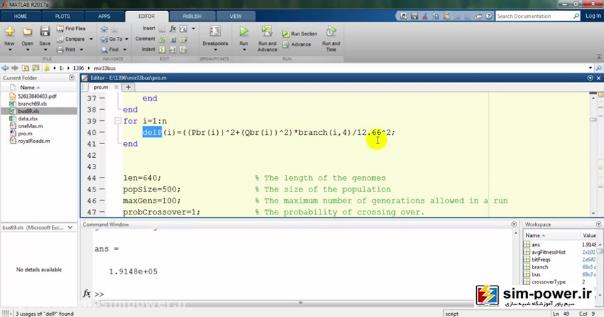
این قسمت که قسمت ژنتیک ماست، تعداد ژنومها را برابر 640 درنظر میگیریم. popSize که population یا جمعیت اولیهی ما قبل از رویش است را برابر 500 در نظر میگیرم. ماکسیمم generationی (maxGens) که قرار هست run بشود و تولید بشود را برابر 100 در نظر گرفتهایم:

میتوانیم آن برابر 1000 در نظر بگیریم. هر چه این عدد بزرگتر باشد، زمانی که طول میکشد تا به آن accuracy برسد بیشتر میشود؛ اما میزان accuracy ما خیلی به عدد صد نزدیک است و میتوانیم با دقت بهتری اندازهگیریهایمان را داشته باشیم. قبلاً دیدید که 100 چقدر طول کشید. حال اگر 1000 بگذارم، خواهید دید که چقدر بیشتر طول میکشد:
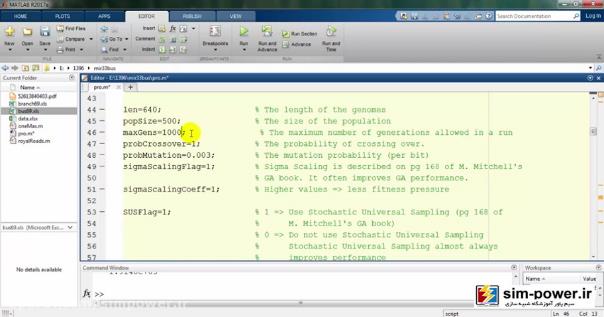
اینجا دوباره باید عددی برای قیمت sectioner وارد کنم:

میبینید که این بار خیلی بیشتر طول خواهد کشید برای اینکه یک accuracy را داشته باشیم:

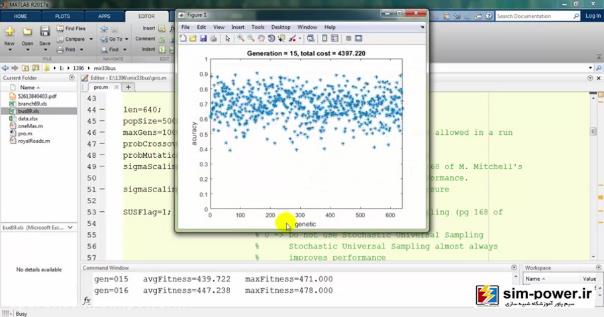
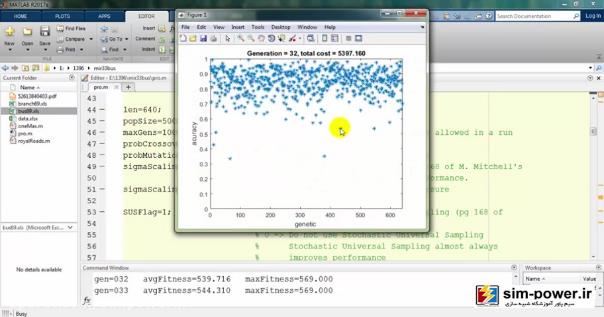

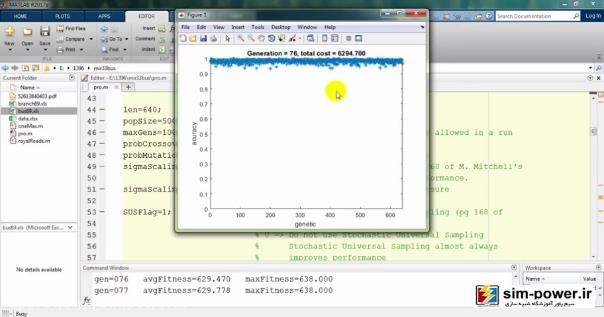
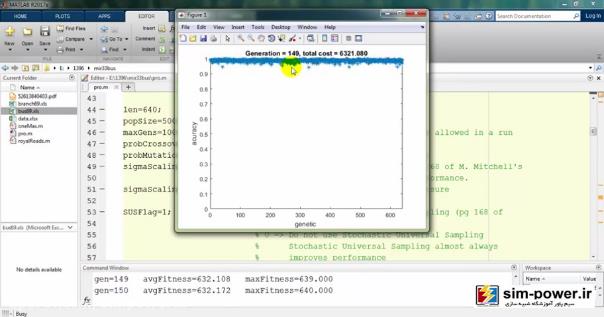
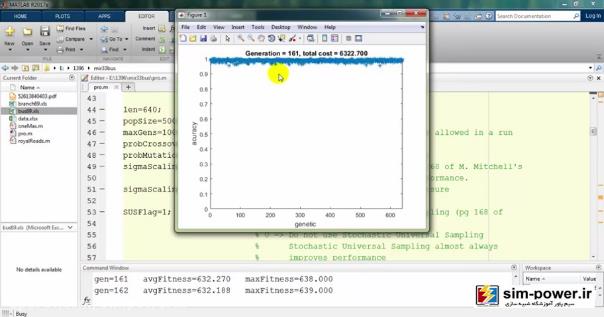
معمولاً بعد از 150-160، چون دیگر دقت خیلی آنچنان فرق نمیکند برای همین میبینید که total cost یا قیمت نهایی ما بر حسب میلیون تومان روی 6 میلیارد مانده و تغییر چندانی ندارد.
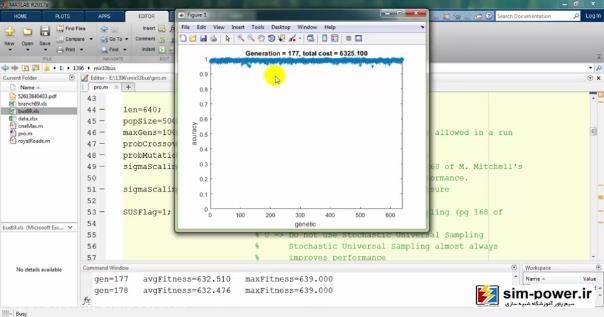
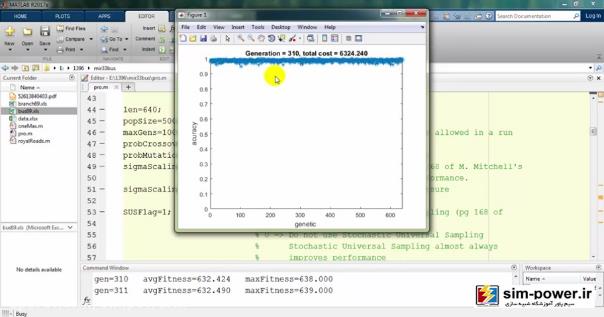

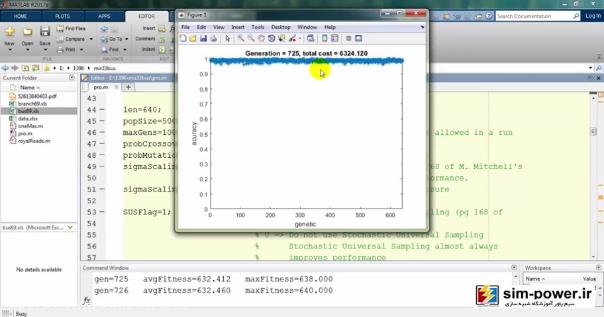
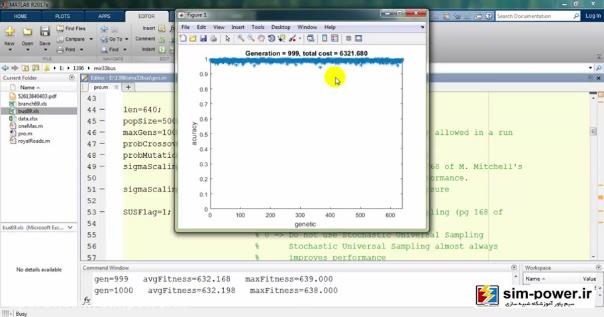
به همین جهت ما تعداد generationهایمان را همان 100 در نظر میگیریم که زمان run ما به شدت کاهش پیدا کند و با یک دقت خیلی خوبی این اندازهگیری را داشته باشیم.
میزان احتمال crossover را برابر 100 درصد میگیریم:
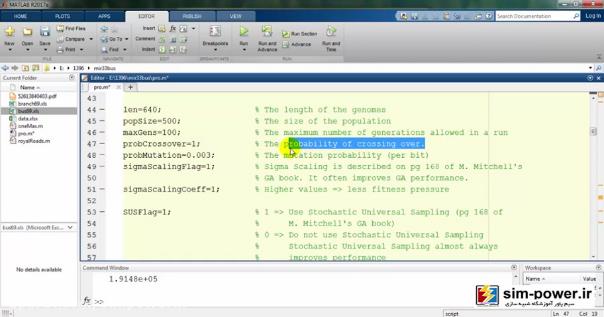
میزان احتمال mutation و sigma scaling را برابر 0.003 و 1 گرفتیم. تقریباً تمام این اعداد استانداردهای ژنتیک هستند و آنها را برابر 1 میگیریم. برای همهی آنها هم نوشتهایم که به هر کدام به چه معناست و از قبل اینها برای متلب تعریف شده که این کدهای ژنتیک به چه نحوی عمل میکنند.
در نهایت بعد از اینکه ژنتیک ما از صفر تا maxGens که برابر 100 در نظرگرفتهایم، در یک loop قرار میگیرد:
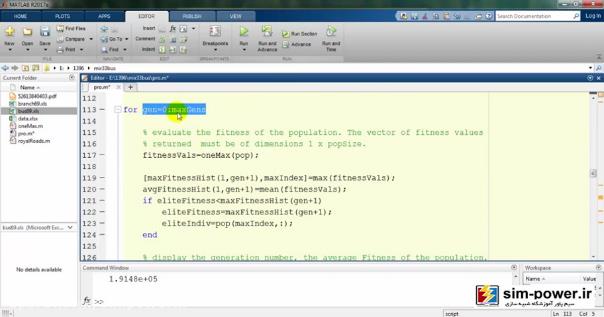
که در آن fitnessVals را برابر پارامتر oneMax قرار میدهد که این oneMax خودش یک تابع است که اینجا تعریف شده است:
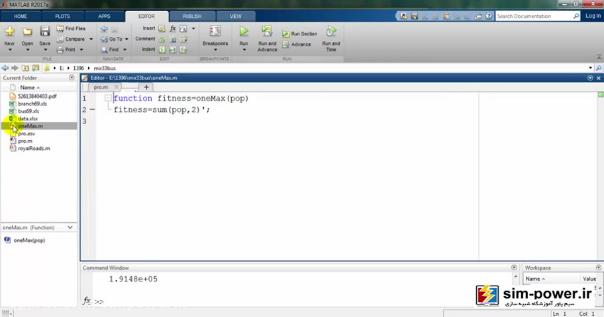
که مجموع pop (population) را برایمان محاسبه میکند، جمع کل جمعیت را.
در نهایت یک تابع هم به نام royalRoads داریم که summationها را به ازای یک تا طول ژنوممان، که تعریف کردهایم، حساب میکند، البته با گام 8، یعنی 8 تا 8 تا:
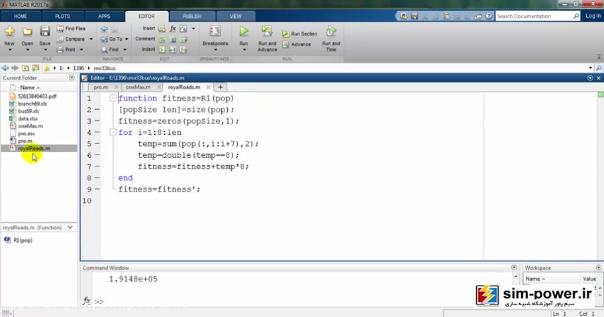
برگردیم به برنامهی اصلی و اینجا یک سری شرطهایی را تعریف کردهایم که اگر eliteFitness کمتر از maxFitness بود آن وقت یکی یکی جلو برو و جمعیت را محاسبه کن تا در نهایت آن میزانی را که قرار است با الگوریتممان به دست بیاوریم تخمین بزنیم:
در نهایت با figure آن را رسم میکنیم. یک figureی را رسم میکنیم:
که قرار است با یک bitFrequency (bitFreqs) یا یک مقدار زمانی که برای هر کدام از این گرافهایی که قرار است نقاشی شود، این را دقیقاً برابر قرار میدهیم و plot را انجام میدهیم. اگر این کار را انجام ندهیم همه plot در یک ثانیه نمایش داده میشود و نمیتوانیم نحوهی رشد جمعیتمان را ببینیم.
axis هم به این جهت است که دقیقاً طول محورهایمان را برابر جمعیتمان بکنیم و title یا عنوانی را برایش میگذاریم و هر کدام از این labelها را هم برای خودمان نامگذاری میکنیم:
و در نهایت figureها را در قسمت printing رسم میکنیم که اینجا میبینید:
زمانی که این را run کنیم، نتایجی تقریباً شبیه به نتایج مقاله میبینید:

که اگر بیایم و اعدادم را تغییر دهم؛ یعنی به ازای هر سکسیونر یک عددی را بگذارم، میبینید که total cost هر دفعه با دفعه قبلی فرق خواهد کرد:

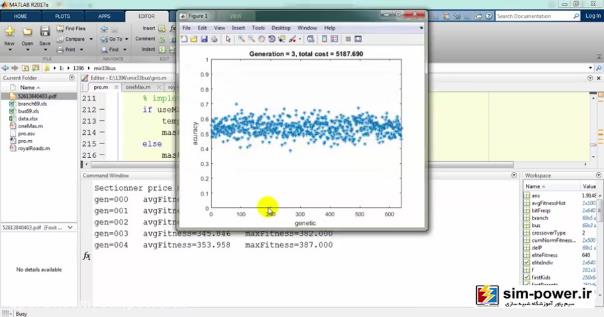
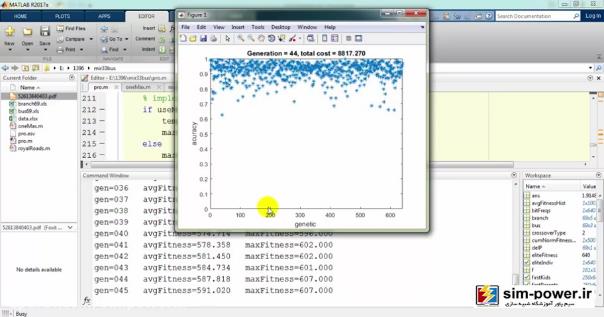
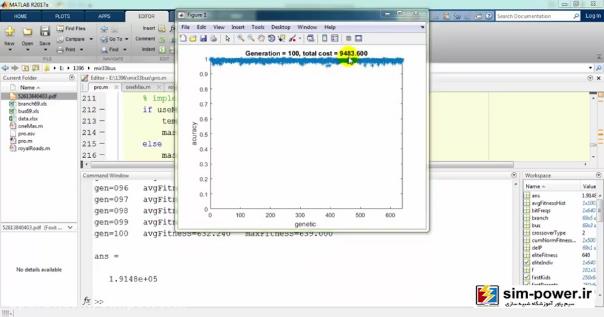
و میبینید که گرافهای رسم شده…:

این مثلاً figure5 است که CENS را بر حسب B بر حسب بیلیون تومان بر حسب فرمولهای مقالهای که داده شده است، ترسیم کردیم:

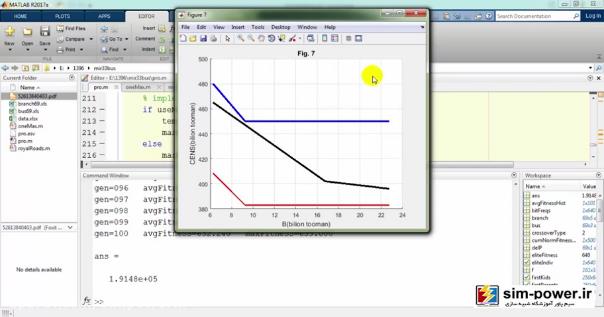
در اینجا میبینید که در نهایت گرافهایی نزدیک به گرافهای خود مقاله بهدست میآید:
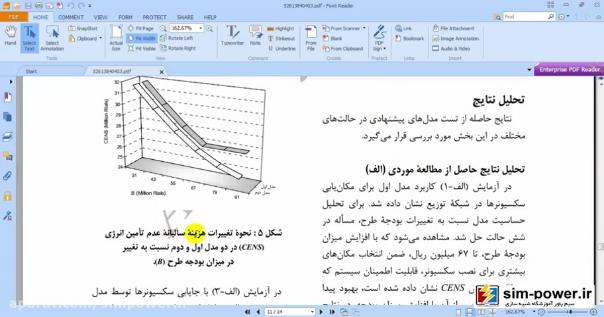
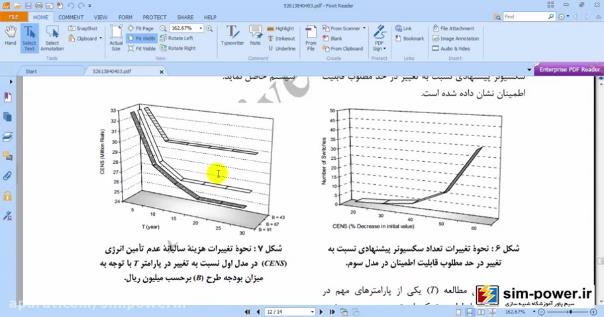
و این نشان میدهد که شبیهسازی ما خیلی به شبیهسازی مقاله نزدیک است و توانستهایم تا حد زیادی به خواستههای مقاله برسیم، با این تفاوت که ما از 69 باسهی ieee استفاده کردهایم و رویهمان با رویهی مقاله به نحوی جداست؛ البته یک بهبودی که ما نسبت به مقاله دادهایم این است که شما میتوانید قیمت سکسیونرهایتان را تغییر دهید، مثلاً 60 میلیون تومان قرار بدهید و total costهای مختلفی را برای شما محاسبه کند:
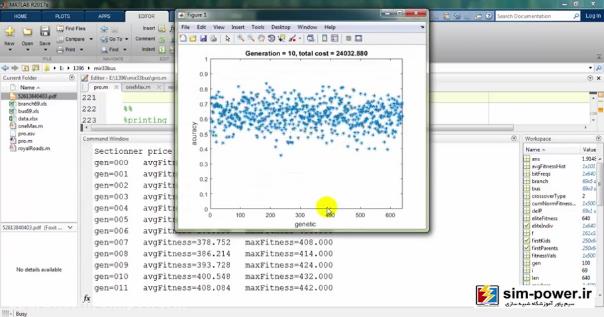


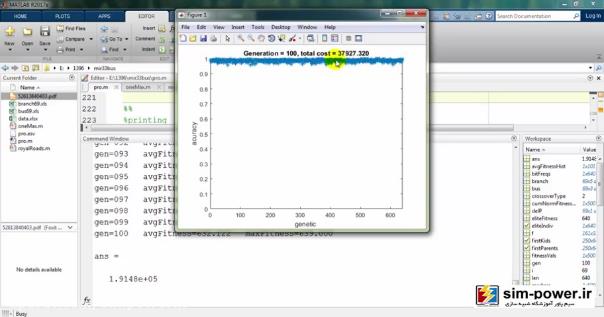
که اعداد هر کدام از این پارامترها با دفعهی قبلی متفاوت خواهد بود که میبینید و ترسیم میشوند:
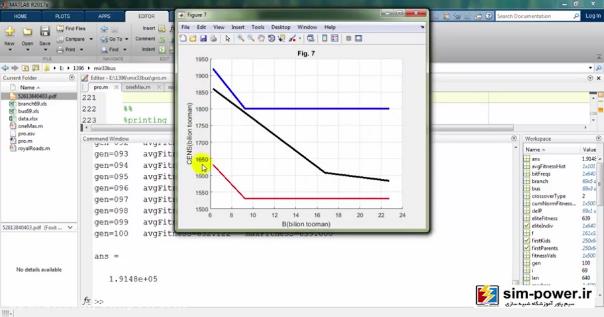

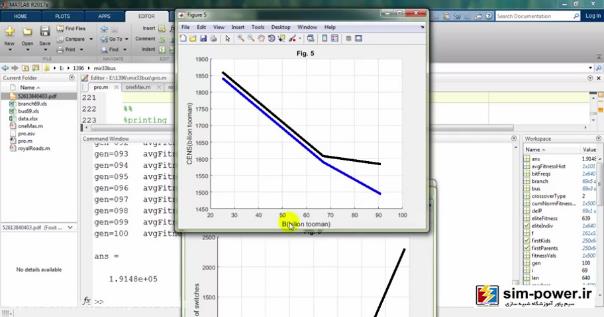
شما میتوانید اعداد مختلفی را بگذارید و هر کدام از این پارامترها را با توجه به تعداد سوئیچهایی که دارید و تعداد CENSهایی که دارید، محاسبه کنید.
امیدوارم که از این شبیهسازی استفاده کنید و هر سوالی هم داشتید میتوانید از بنده بپرسید.